Brug dynamiske områdenavne i Excel til fleksible dropdowns
Excel -regneark inkluderer ofte rullemenuer for at forenkle og/eller standardisere dataindtastning. Disse rullemenuer oprettes ved hjælp af datavalideringsfunktionen for at angive en liste over tilladte poster.
For at opsætte en simpel rulleliste skal du vælge den celle, hvor data skal indtastes, derefter klikke på Datavalidering(Data Validation) (på fanen Data ), vælge Datavalidering(Data Validation) , vælge Liste(List) (under Tillad(Allow) :), og derefter indtaste listeelementerne (adskilt af kommaer) ) i feltet Kilde(Source) : (se figur 1).
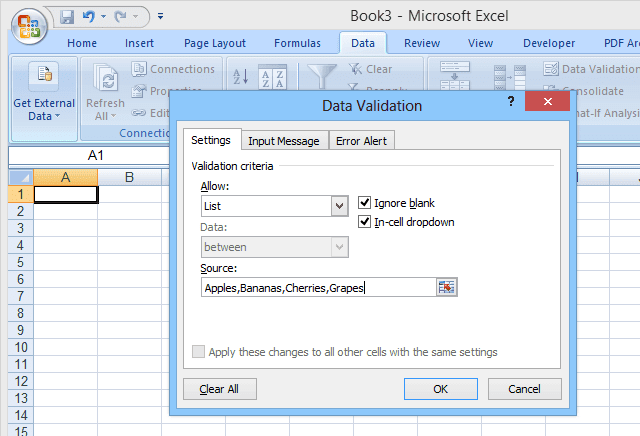
I denne type grundlæggende dropdown er listen over tilladte poster angivet i selve datavalideringen; Derfor skal brugeren åbne og redigere datavalideringen for at foretage ændringer i listen. Dette kan dog være svært for uerfarne brugere eller i tilfælde, hvor listen over valgmuligheder er lang.
En anden mulighed er at placere listen i et navngivet område i regnearket(named range within the spreadsheet) og derefter angive dette områdenavn (forordet med et lighedstegn) i feltet Kilde(Source) : i datavalideringen (som vist i figur 2(Figure 2) ).

Denne anden metode gør det lettere at redigere valgene på listen, men tilføjelse eller fjernelse af elementer kan være problematisk. Da det navngivne område ( FruitChoices , i vores eksempel) refererer til et fast celleområde ($H$3:$H$10 som vist), vil de ikke vises i rullemenuen , hvis der tilføjes flere valgmuligheder til cellerne H11 eller derunder. (da disse celler ikke er en del af FruitChoices- serien).
Ligeledes hvis f.eks. Pærer(Pears) og Jordbær-(Strawberries) indtastninger slettes, vises de ikke længere i rullemenuen, men i stedet vil rullemenuen indeholde to "tomme" valg, da rullemenuen stadig refererer til hele FruitChoices-området, inklusive de tomme celler H9 og H10 .
Af disse grunde, når du bruger et normalt navngivet område som listekilde for en dropdown, skal selve det navngivne område redigeres for at inkludere flere eller færre celler, hvis poster tilføjes eller slettes fra listen.
En løsning på dette problem er at bruge et dynamisk(dynamic) områdenavn som kilde til dropdown-valgene. Et dynamisk områdenavn er et, der automatisk udvides (eller trækkes sammen) for nøjagtigt at matche størrelsen på en datablok, efterhånden som indgange tilføjes eller fjernes. For at gøre dette skal du bruge en formel(formula) i stedet for et fast område af celleadresser til at definere det navngivne område.
Sådan opsætter du et dynamisk område(Dynamic Range) i Excel
Et normalt (statisk) områdenavn refererer til et specificeret celleområde ($H$3:$H$10 i vores eksempel, se nedenfor):

Men et dynamisk område er defineret ved hjælp af en formel (se nedenfor, taget fra et separat regneark, der bruger dynamiske områdenavne):

Før vi går i gang, skal du sørge for at downloade vores Excel-eksempelfil (sorteringsmakroer er blevet deaktiveret).
Lad os undersøge denne formel i detaljer. Valgene for Frugt er i en blok af celler direkte under en overskrift ( FRUITS ). Denne overskrift er også tildelt et navn: FruitsHeading :

Hele formlen, der bruges til at definere det dynamiske område for Frugt-(Fruits) valgene, er:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(OFFSET(FruitsHeading,1,0,20,1)),0,0),0)-1,20),1)
FruitsHeading refererer til overskriften, der er en række over den første post på listen. Tallet 20 (brugt to gange i formlen) er den maksimale størrelse (antal rækker) for listen (dette kan justeres efter ønske).
Bemærk, at i dette eksempel er der kun 8 poster på listen, men der er også tomme celler under disse, hvor yderligere poster kan tilføjes. Tallet 20 refererer til hele blokken, hvor der kan indtastes, ikke til det faktiske antal poster.
Lad os nu opdele formlen i stykker (farvekodning af hvert stykke), for at forstå, hvordan det virker:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(OFFSET(FruitsHeading,1,0,20,1)),0,0),0)-1,20),1)
Det "inderste" stykke er OFFSET(FruitsHeading,1,0,20,1) . Dette refererer til blokken med 20 celler (under FruitsHeading -cellen), hvor valg kan indtastes. Denne OFFSET - funktion siger grundlæggende: Start ved FruitsHeading -cellen, gå 1 række ned og over 0 kolonner, og vælg derefter et område, der er 20 rækker langt og 1 kolonne bredt. Så det giver os den 20-rækkede blok, hvor Frugt(Fruits) - valgene indtastes.
Det næste stykke af formlen er ISBLANK- funktionen:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(the above),0,0),0)-1,20),1)
Her er OFFSET- funktionen (forklaret ovenfor) blevet erstattet med "ovenstående" (for at gøre tingene lettere at læse). Men ISBLANK -funktionen fungerer på det 20-rækkers celleområde, som OFFSET - funktionen definerer.
ISBLANK opretter derefter et sæt af 20 SAND-(TRUE) og FALSK(FALSE) -værdier, der angiver, om hver af de individuelle celler i 20-rækkernes område, der refereres til af OFFSET - funktionen, er tom (tom) eller ej. I dette eksempel vil de første 8 værdier i sættet være FALSK(FALSE) , da de første 8 celler ikke er tomme, og de sidste 12 værdier vil være TRUE .
Det næste stykke af formlen er INDEX- funktionen:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,INDEX(the above,0,0),0)-1,20),1)
Igen henviser "ovenstående" til ISBLANK- og OFFSET- funktionerne beskrevet ovenfor. INDEX - funktionen returnerer et array, der indeholder de 20 TRUE / FALSE - værdier, der er oprettet af ISBLANK- funktionen.
INDEX bruges normalt til at vælge en bestemt værdi (eller værdiområde) ud af en datablok ved at angive en bestemt række og kolonne (inden for denne blok). Men indstilling af række- og kolonneinput til nul (som det gøres her) får INDEX til at returnere et array, der indeholder hele datablokken.
Det næste stykke af formlen er MATCH- funktionen:
=OFFSET(FruitsHeading,1,0,IFERROR(MATCH(TRUE,the above,0)-1,20),1)
MATCH - funktionen returnerer positionen af den første SAND(TRUE) -værdi inden for det array, der returneres af INDEX - funktionen. Da de første 8 poster på listen ikke er tomme, vil de første 8 værdier i arrayet være FALSE , og den niende værdi vil være TRUE (da den 9. række i området er tom).
Så MATCH- funktionen returnerer værdien af 9 . I dette tilfælde vil vi dog rigtig gerne vide, hvor mange poster der er på listen, så formlen trækker 1 fra MATCH- værdien (som giver positionen for den sidste post). Så i sidste ende returnerer MATCH ( TRUE ,ovenstående,0)-1 værdien af 8 .
Det næste stykke af formlen er IFERROR- funktionen:
=OFFSET(FruitsHeading,1,0,IFERROR(the above,20),1)
Funktionen HVISER(IFERROR) returnerer en alternativ værdi, hvis den første angivne værdi resulterer i en fejl. Denne funktion er inkluderet, da hvis hele blokken af celler (alle 20 rækker) er fyldt med poster, vil MATCH - funktionen returnere en fejl.
Dette skyldes, at vi fortæller MATCH- funktionen at lede efter den første TRUE -værdi (i rækken af værdier fra ISBLANK- funktionen), men hvis INGEN(NONE) af cellerne er tomme, vil hele arrayet være fyldt med FALSE - værdier. Hvis MATCH ikke kan finde målværdien ( TRUE ) i det array, det søger, returnerer det en fejl.
Så hvis hele listen er fuld (og derfor returnerer MATCH en fejl), vil HVIS-(IFERROR) funktionen i stedet returnere værdien 20 (velvidende at der skal være 20 poster på listen).
Til sidst returnerer OFFSET(FruitsHeading,1,0,the above,1) det område, vi faktisk leder efter: Start ved FruitsHeading -cellen, gå 1 række ned og over 0 kolonner, og vælg derefter et område, der dog er mange rækker langt som der er poster i listen (og 1 kolonne bred). Så hele formlen tilsammen vil returnere det område, der kun indeholder de faktiske poster (ned til den første tomme celle).
Ved at bruge denne formel til at definere det område, der er kilden til rullemenuen, betyder det, at du frit kan redigere listen (tilføje eller fjerne poster, så længe de resterende poster starter i den øverste celle og er sammenhængende), og rullemenuen vil altid afspejle den aktuelle liste (se figur 6(Figure 6) ).

Eksempelfilen (Dynamiske lister) , der er blevet brugt her, er inkluderet og kan downloades fra denne hjemmeside. Makroerne virker dog ikke, fordi WordPress ikke kan lide Excel- bøger med makroer i.
Som et alternativ til at angive antallet af rækker i listeblokken, kan listeblokken tildeles sit eget områdenavn, som derefter kan bruges i en ændret formel. I eksempelfilen bruger en anden liste ( Names ) denne metode. Her tildeles hele listeblokken (under "NAMES"-overskriften, 40 rækker i eksempelfilen) områdenavnet NameBlock . Den alternative formel til at definere navnelisten(NamesList) er så:
=OFFSET(NamesHeading,1,0,IFERROR(MATCH(TRUE,INDEX(ISBLANK(NamesBlock),0,0),0)-1,ROWS(NamesBlock)),1)
hvor NamesBlock erstatter OFFSET ( FruitsHeading,1,0,20,1 ) og ROWS(NamesBlock) erstatter de 20 (antal rækker) i den tidligere formel.
Så for dropdown-lister, som nemt kan redigeres (inklusive af andre brugere, som måske er uerfarne), prøv at bruge dynamiske områdenavne! Og bemærk, at selvom denne artikel har været fokuseret på dropdown-lister, kan dynamiske områdenavne bruges overalt, hvor du har brug for at referere til et område eller en liste, der kan variere i størrelse. God fornøjelse!

About the author
"Jeg er freelance-ekspert i Windows og Office. Jeg har over 10 års erfaring med at arbejde med disse værktøjer og kan hjælpe dig med at få mest muligt ud af dem. Mine færdigheder omfatter: at arbejde med Microsoft Word, Excel, PowerPoint og Outlook; skabe web sider og applikationer; og hjælpe kunder med at nå deres forretningsmål."
Related posts
Sådan slettes tomme linjer i Excel
Sådan bruger du Excels Tal Cells-funktion
Sådan indsætter du et Excel-regneark i et Word-dokument
Sådan bruges Excels What-If-analyse
Sådan rettes en række i Excel
Grundlæggende én-kolonne og multi-kolonne datasortering i Excel-regneark
4 måder at bruge et flueben i Excel
Sådan sorteres efter dato i Excel
Brug tastaturet til at ændre rækkehøjde og kolonnebredde i Excel
2 måder at bruge Excels transponeringsfunktion
Sådan opretter du en VBA-makro eller et script i Excel
Sådan rettes #N/A-fejl i Excel-formler som VLOOKUP
Hvornår skal man bruge Index-Match i stedet for VLOOKUP i Excel
Sådan skriver du en IF-formel/-erklæring i Excel
Tilslutning af Excel til MySQL
Sådan indsætter du CSV eller TSV i et Excel-regneark
Brug Spike til at klippe og indsætte flere tekstelementer i Word
Hvad er et VBA-array i Excel, og hvordan programmeres et
Gruppér rækker og kolonner i et Excel-regneark
Sådan opretter du flere linkede rullelister i Excel